Plotting¶
questions:
“How can I plot my data?”
“How can I save my plot for publishing?”
objectives:
“Create a time series plot showing a single data set.”
“Create a scatter plot showing relationship between two data sets.”
keypoints:
“
matplotlibis the most widely used scientific plotting library in Python.”“Plot data directly from a Pandas dataframe.”
“Select and transform data, then plot it.”
“Many styles of plot are available: see the Python Graph Gallery for more options.”
“Can plot many sets of data together.”
matplotlib is the most widely used scientific plotting library in Python.¶
Commonly use a sub-library called
matplotlib.pyplot.The Jupyter Notebook will render plots inline if we ask it to using a “magic” command.
%matplotlib inline
import matplotlib.pyplot as plt
Simple plots are then (fairly) simple to create.
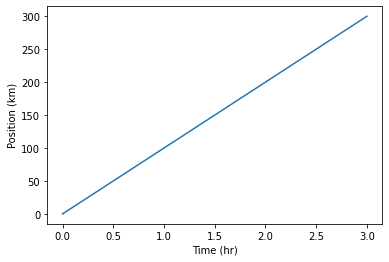
time = [0, 1, 2, 3]
position = [0, 100, 200, 300]
plt.plot(time, position)
plt.xlabel('Time (hr)')
plt.ylabel('Position (km)')
Text(0, 0.5, 'Position (km)')
Note: Display All Open Figures
In our Jupyter Notebook example with %matplotlib inline, running the cell generates the figure directly below the code. The figure is also included in the Notebook document for future viewing. However, other Python environments require an additional command in order to display the figure.
plt.show()
Plot data directly from a Pandas dataframe.¶
We can also plot Pandas dataframes.
This implicitly uses
matplotlib.pyplot.Before plotting, we convert the column headings from a
stringtointegerdata type, since they represent numerical values
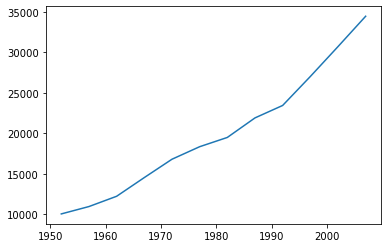
import pandas as pd
data = pd.read_csv('data/gapminder_gdp_oceania.csv', index_col='country')
# Extract year from last 4 characters of each column name
# The current column names are structured as 'gdpPercap_(year)',
# so we want to keep the (year) part only for clarity when plotting GDP vs. years
# To do this we use strip(), which removes from the string the characters stated in the argument
# This method works on strings, so we call str before strip()
years = data.columns.str.strip('gdpPercap_')
# Convert year values to integers, saving results back to dataframe
data.columns = years.astype(int)
data.loc['Australia'].plot()
<matplotlib.axes._subplots.AxesSubplot at 0x140841fd040>
Select and transform data, then plot it.¶
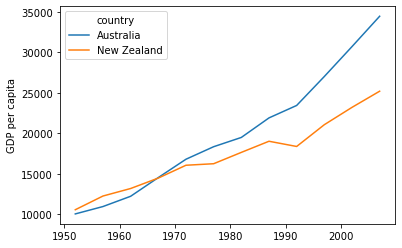
By default,
DataFrame.plotplots with the rows as the X axis.We can transpose the data in order to plot multiple series.
data.T.plot()
plt.ylabel('GDP per capita')
Text(0, 0.5, 'GDP per capita')
Many styles of plot are available.¶
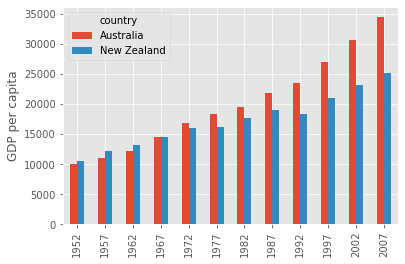
For example, do a bar plot using a fancier style.
plt.style.use('ggplot')
data.T.plot(kind='bar')
plt.ylabel('GDP per capita')
Text(0, 0.5, 'GDP per capita')
Data can also be plotted by calling the matplotlib plot function directly.¶
The command is
plt.plot(x, y)The color and format of markers can also be specified as an additional optional argument e.g.,
b-is a blue line,g--is a green dashed line.
Get Australia data from dataframe¶
years = data.columns
gdp_australia = data.loc['Australia']
plt.plot(years, gdp_australia, 'g--')
[<matplotlib.lines.Line2D at 0x140843afac0>]
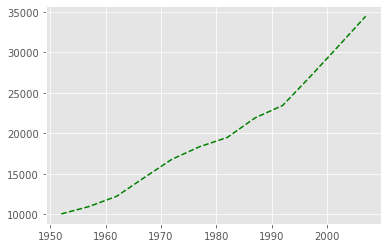
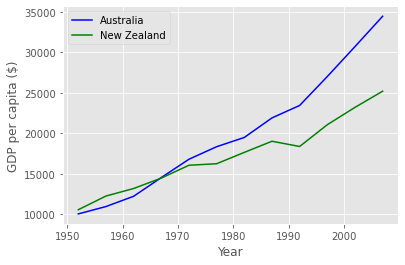
Can plot many sets of data together.¶
# Select two countries' worth of data.
gdp_australia = data.loc['Australia']
gdp_nz = data.loc['New Zealand']
# Plot with differently-colored markers.
plt.plot(years, gdp_australia, 'b-', label='Australia')
plt.plot(years, gdp_nz, 'g-', label='New Zealand')
# Create legend.
plt.legend(loc='upper left')
plt.xlabel('Year')
plt.ylabel('GDP per capita ($)')
Text(0, 0.5, 'GDP per capita ($)')
Adding a Legend¶
Often when plotting multiple datasets on the same figure it is desirable to have a legend describing the data. This can be done in matplotlib in two stages:
Provide a label for each dataset in the figure:
plt.plot(years, gdp_australia, label='Australia')
plt.plot(years, gdp_nz, label='New Zealand')
Instruct
matplotlibto create the legend.
plt.legend()
By default matplotlib will attempt to place the legend in a suitable position. If you
would rather specify a position this can be done with the loc= argument, e.g to place
the legend in the upper left corner of the plot, specify loc='upper left'
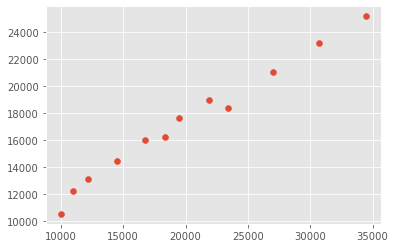
Plot a scatter plot correlating the GDP of Australia and New Zealand
Use either
plt.scatterorDataFrame.plot.scatter
plt.scatter(gdp_australia, gdp_nz)
<matplotlib.collections.PathCollection at 0x14085553bb0>
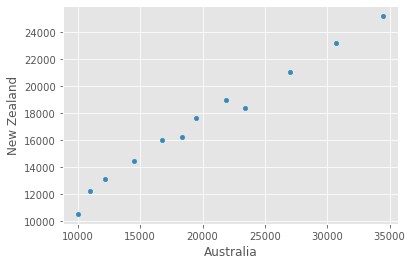
data.T.plot.scatter(x = 'Australia', y = 'New Zealand')
<matplotlib.axes._subplots.AxesSubplot at 0x1408452a700>
Exercise: Minima and Maxima
Fill in the blanks below to plot the minimum GDP per capita over time for all the countries in Europe. Modify it again to plot the maximum GDP per capita over time for Europe.
data_europe = pd.read_csv('data/gapminder_gdp_europe.csv', index_col='country')
data_europe.____.plot(label='min')
data_europe.____
plt.legend(loc='best')
plt.xticks(rotation=90)
See Solution
data_europe = pd.read_csv('data/gapminder_gdp_europe.csv', index_col='country')
data_europe.min().plot(label='min')
data_europe.max().plot(label='max')
plt.legend(loc='best')
plt.xticks(rotation=90)
Exercise: Correlations
Modify the example in the notes to create a scatter plot showing the relationship between the minimum and maximum GDP per capita among the countries in Asia for each year in the data set. What relationship do you see (if any)?
data_asia = pd.read_csv('data/gapminder_gdp_asia.csv', index_col='country')
data_asia.describe().T.plot(kind='scatter', x='min', y='max')
See Solution
No particular correlations can be seen between the minimum and maximum gdp values year on year. It seems the fortunes of asian countries do not rise and fall together.
You might note that the variability in the maximum is much higher than that of the minimum. Take a look at the maximum and the max indexes:
data_asia = pd.read_csv('data/gapminder_gdp_asia.csv', index_col='country')
data_asia.max().plot()
print(data_asia.idxmax())
print(data_asia.idxmin())